


رگرسیون منطقی: طبقهبندی کننده درخت تصمیمگیری[1]
یک درخت تصمیمگیری درواقع یک فلوچارت درخت دودوئی است که در آن هر گره گروهی از مشاهدات را طبق برخی از متغیرهای ویژگی تقسیم میکند. در اینجا ما در حال ساخت طبقهبندی کننده درخت تصمیمگیری برای پیشبینی زن یا مرد بودن هستیم. ما یک مجموعه داده بسیار کوچک با 19 نمونه خواهیم گرفت. این نمونهها شامل دو ویژگی “قد” و “طول مو” است.
پیشنیاز
برای ساخت طبقهبندی کننده زیر، باید pydotplus و Graphviz را نصب کنیم. در اصل Graphviz ابزاری برای ترسیم گرافیک با استفاده از فایلهای dot است و pydotplus ماژولی برای زبان نقطه[2] Graphviz است. میتوان آن را از طریق Package Manager یا pip نصب کرد. اکنون میتوان طبقهبندی کننده درخت تصمیمگیری را با کمک کد پایتون زیر ساخت. برای شروع اجازه دهید چند کتابخانه مهم را به شرح زیر وارد کنیم –
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collections
اکنون ما باید دادهها را به شرح زیر ارائه دهیم –
X = [[165,19], [175,32], [136,35], [174,65], [141,28], [176,15], [131,32],
[166,6], [128,32], [179,10], [136,34], [186,2], [126,25], [176,28], [112,38],
[169,9], [171,36], [116,25], [196,25]]
Y = [‘Man’,’Woman’,’Woman’,’Man’,’Woman’,’Man’,’Woman’,’Man’,’Woman’,
‘Man’,’Woman’,’Man’,’Woman’,’Woman’,’Woman’,’Man’,’Woman’,’Woman’,’Man’]
data_feature_names = [‘height’,’length of hair’]
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)
پس از تهیه دیتاست، ما باید مدل را که میتواند به شرح زیر انجام شود، fit کنیم –
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)
پیشبینی را میتوان با کمک کد پایتون زیر انجام داد –
prediction = clf.predict([[133,37]])
print(prediction)
ما میتوانیم به کمک کد پایتون زیر درخت تصمیمگیری را تصویرسازی کنیم –
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = (‘orange’, ‘yellow’)
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png(‘Decisiontree16.png’)
کد فوق پیشبینی ] “Woman”[را ارائه داده و درخت تصمیمگیری زیر را ایجاد میکند –
درخت تصمیمگیری[3]
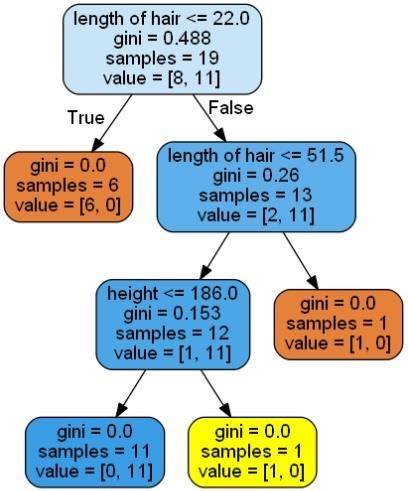
ما میتوانیم مقادیر ویژگیها را برای آزمودنِ آنها تغییر دهیم.
طبقهبندی کننده جنگل تصادفی
همانطور که میدانیم متدهای ensemble متدهایی هستند که مدلهای یادگیری ماشین را در یک مدل یادگیری ماشین قدرتمندتر ترکیب میکنند. جنگل تصادفی به معنی مجموعهای از درختان تصمیمگیری، یکی از آنها است. جنگل تصادفی بهتر از یک درخت تصمیمگیری است، زیرا ضمن حفظ قدرتهای پیشبینی کننده، میتواند با میانگین گرفتن از نتایج، over-fitting (دادههایی که پراکندگی کمی دارند) را کاهش دهد. در اینجا ما در حال اجرای مدل جنگل تصادفی در دیتاست سرطان Scikit Learn هستیم.
پکیجهای ضروری را import کنید –
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as np
اکنون ما باید دیتاستی ارائه دهیم که میتواند به شرح زیر انجام شود –
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)
پس از تهیه دیتاسِت، باید مدل را که میتواند مانند زیر باشد، fit کنیم.
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)
حالا دقت را روی مجموعه training و زیرمجموعه test به دست میآوریم. اگر ما تعداد تخمین زنندهها را افزایش دهیم دقت زیرمجموعه آزمایش هم افزایش خواهد یافت.
print(‘Accuracy on the training subset: (:.3f)’,format(forest.score(X_train,y_train)))
print(‘Accuracy on the training subset: (:.3f)’,format(forest.score(X_test,y_test)))
خروجی
Accuracy on the training subset: (:.3f) 1.0
Accuracy on the training subset: (:.3f) 0.965034965034965
حالا مانند درخت تصمیمگیری، جنگل تصادفی دارای ماژول feature_importance است که دید بهتری از وزن ویژگیها نسبت به درخت تصمیمگیری ارائه میدهد که میتواند به شکل زیر ترسیم و تجسم شود –
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align=’center’)
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel(‘Feature Importance’)
plt.ylabel(‘Feature’)
plt.show()
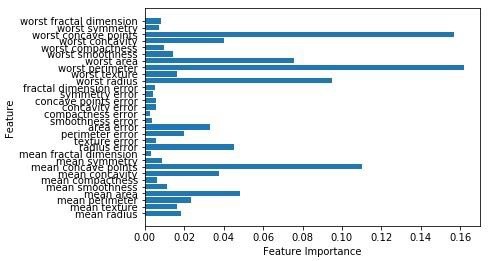
بخشهای دیگر مقاله را از لینکهای زیر بخوانید:
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت اول)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت دوم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت سوم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت چهارم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت آخر)
[1] Decision Tree Classifier
[2] Dot Language
[3] Decision Tree



