


بردار ماشین پشتیبانی[۱] (SVM)
ماشین بردار پشتیبان هم برای مسائل طبقهبندی و هم برای مسائل رگرسیون استفاده میشود. اما عمدتاً برای مسائل طبقهبندی استفاده میشود. مفهوم اصلی SVM این است که هر یک آیتمهای داده را بهعنوان یک نقطه در فضای n بُعدی با مقدار هر ویژگی که مقدار یک مختصات خاص است، ترسیم کنیم. در اینجا n ویژگیهایی است که میتوانیم داشته باشیم. تصویری که در ادامه نشان داده میشود، نمایش گرافیکی برای درک مفهوم SVM است.
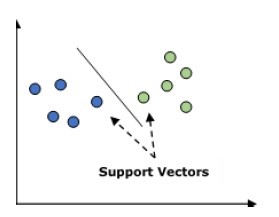
در نمودار بالا ما دو ویژگی داریم بنابراین ما باید این دو متغیر را در فضای دو بُعدی که در آن هر نقطه دارای دو مختصات به نام بردارهای پشتیبان است، رسم کنیم. این خط دادهها را به دو گروه طبقهبندیشده تقسیم میکند. این خط طبقهبندی کننده خواهد بود.
بیز ساده
این هم یک روش طبقهبندی است. منطق پشت تکنیک طبقهبندی استفاده از نظریه بیز برای ساخت طبقهبندی کنندهها است. فرض بر این است پیشگوییکنندگان[۲] مستقل هستند. به عبارت ساده، فرض بر این است که حضور یک ویژگی خاص در یک کلاس باوجود هر ویژگی دیگر ارتباطی ندارد، یعنی ویژگیها مستقل از هم هستند. معادله تئوری بیز در زیر آمده است:
P(AB)=P(BA)P(A)P(B)
ساخت مدل بیز ساده، آسان است و مخصوصاً برای دیتاستهای بزرگ مفید است.
K نزدیکترین همسایه[۳] هم برای مسائل طبقهبندی و هم برای مسائل رگرسیون استفاده میشود و بهطور گستردهای برای حل مسائل طبقهبندی استفاده میشود. مفهوم اصلی الگوریتم این است که برای ذخیره تمام موارد در دسترس و طبقهبندی موارد جدید با آراء K همسایهاش استفاده میشود. سپس مورد به کلاسی تعلق میگیرد که بین K نزدیکترین همسایهاش بیشترین اشتراک را داشته باشد که این اشتراک با تابع فاصله اندازهگیری میشود. تابع فاصله میتواند اقلیدسی، مینکوفسکی و فاصله همینگ باشد. مطلبی که در ادامه میآید را برای محاسبه KNN در نظر بگیرید.
KNN محاسباتی نسبت به سایر الگوریتمهای مورداستفاده برای مسائل طبقهبندی هزینه بیشتری دارد. نرمالسازی متغیرها در اینجا لازم است در غیراینصورت متغیرهای سطوح بالاتر میتوانند آن را بایاس کنند. در KNN ما باید روی مرحله پیشپردازش مانند حذف نویز کارکنیم.
خوشهبندی K-Means
همانطور که از نام آن پیداست، برای حل مسائل خوشهبندی استفاده میشود. اساساً نوعی یادگیری بدون نظارت است. خوشهبندی K-Means اساساً نوعی از یادگیری بدون نظارت است. منطق اصلی الگوریتم خوشهبندی K-Means این است که مجموعه دادهها را از طریق تعدادی از خوشهها طبقهبندی کند. مراحل زیر را برای شکل دادن خوشه بهوسیله K-Means انجام دهید.
- K-Means برای هر خوشه تعداد K نقطه را که سنتروید[۴] نام دارد برای هر خوشه برمیدارد.
- حالا هر نقطه داده با نزدیک با نزدیکترین سنتروید یک خوشه را شکل میدهند یعنی k خوشه.
- حالا الگوریتم سنترویدهای هر خوشه را بر اساس اعضای موجودِ خوشه پیدا خواهد کرد.
ما باید این گامها را تکرار کنیم تا همگرایی اتفاق بیفتد.
جنگل تصادفی
اینیک الگوریتم طبقهبندی نظارتشده است. مزیت الگوریتم جنگل تصادفی این است که میتواند برای هر دو نوع طبقهبندی و رگرسیون مورداستفاده قرار گیرد. اساساً مجموعهای از درختهای تصمیمگیری (بهعبارتدیگر جنگل) است یا میتوانید بگویید گروهی از درختهای تصمیمگیری. مفهوم اصلی جنگل تصادفی این است که هر درخت طبقهبندی میکند و جنگل بهترین طبقهبندیها را از بین آنها انتخاب میکند. در ادامه مزایای الگوریتم جنگل تصادفی آمده است. طبقهبندی کننده جنگل تصادفی میتواند برای وظایف طبقهبندی و رگرسیون بهکاربرده شود. این الگوریتمها میتوانند مقادیر گمشده را اداره کنند. این الگوریتم مدل را Overfit نمیکند، حتی اگر تعداد درختان بیشتری در جنگل داشته باشیم.
قسمتهای دیگر این مقاله آموزشی را از لینکهای زیر بخوانید:
هوش مصنوعی با پایتون، بخش سوم – یادگیری ماشین (قسمت اول)
هوش مصنوعی با پایتون، بخش سوم – یادگیری ماشین (قسمت دوم)
[۱] Support Vector Machine
[۲] Predictors
[۳] K-Nearest Neighbors
[۴] Centroid



