ماشینهای بردار پشتیبان (SVM[1])
ماشین بردار پشتیبان (SVM) در اصل یک الگوریتم یادگیری ماشین نظارتشده است که میتواند برای هر دو روش رگرسیون و طبقهبندی استفاده شود. مفهوم اصلی SVM ترسیم هر مورد داده بهعنوان نقطهای در فضای n بُعدی است بهطوریکه هر ویژگی مقدار یک مختصات خاص باشد. در اینجا n ویژگیهایی است که ما داریم. در زیر یک نمایش گرافیکی ساده برای درک مفهوم SVM وجود دارد.
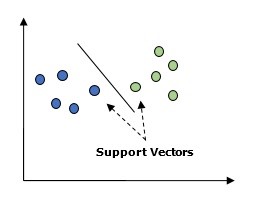
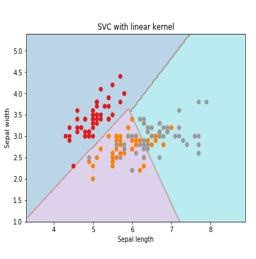
در نمودار بالا دو ویژگی داریم، بنابراین ابتدا باید این دو متغیر را در فضای دوبُعدی ترسیم کنیم که در هر نقطه دو مختصات داریم به نامهای بردارهای پشتیبان. خط دادهها را به دو گروه طبقهبندیشده مختلف تقسیم کنید، این خط میتواند طبقهبندی شود. در اینجا ما قصد داریم با استفاده از مجموعه دادههای Scikit-Learn و دیتاست گیاه iris یک طبقهبندی کننده SVM بسازیم. کتابخانه Scikit-Learn دارای ماژول sklearn.svm است و sklearn.svm.svc را برای طبقهبندی فراهم میکند. طبقهبندی SVM برای پیشبینیِ کلاس گیاه iris بر اساس چهار ویژگی در زیر نشان داده شده است.
دیتاست
ما در این مثال از دیتاست iris استفاده میکنیم که شامل 3 کلاس 50 نمونهای است که در آن هر کلاس بهنوعی از گیاه iris اشاره دارد. هر نمونه دارای 4 ویژگی است به نامهای طول کاسبرگ، عرض کاسبرگ، طول گلبرگ و عرض گلبرگ. طبقهبندی کننده SVM برای پیشبینی کلاس گیاه iris بر اساس 4 ویژگی در تصویر قسمت SVC با Kernel خطی نشان داده شده است.
Kernel
این تکنیکی است که توسط SVM استفادهشده است. اساساً اینها توابعی هستند که ورودی با ابعاد کم (کوچک) میگیرند و آن را به فضایی با بُعد بالاتر تبدیل میکنند. این کار مسئله تفکیکناپذیر را به تفکیکپذیر تبدیل میکند. تابع Kernel میتواند هر نوع تابعی از بین توابع خطی، چندجملهای، rbf و sigmoid باشد. در این مثال ما از Kernel خطی استفاده خواهیم کرد.
اکنون پکیجهای زیر را Import کنید-
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt
حالا، دادههای ورودی را بارگذاری کنید-
iris = datasets.load_iris()
ما دو ویژگی اول را برمیداریم-
X = iris.data[:,:2]
y = iris.target
ما حدود ماشین بردار پشتیبانی را با دادههای اصلی ترسیم خواهیم کرد. ما در حال ایجاد یک شبکه[1] برای ترسیم هستیم.
x_min, x_max = X[:, 0].min() – 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() – 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
ما باید مقدار پارامتر تنظیم بدهیم.
C = 1.0
و همچنین ما باید یک شیء طبقهبندی کننده SVM ایجاد کنیم.
Svc_classifier = svm_classifier.SVC(kernel=’linear’,
C=C, decision_function_shape = ‘ovr’).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel(‘Sepal length’)
plt.ylabel(‘Sepal width’)
plt.xlim(xx.min(), xx.max())
plt.title(‘SVC with linear kernel’)
Svc_classifier = svm_classifier.SVC(kernel=’linear’,
C=C, decision_function_shape = ‘ovr’).fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel(‘Sepal length’)
plt.ylabel(‘Sepal width’)
plt.xlim(xx.min(), xx.max())
plt.title(‘SVC with linear kernel’)
SVC با Kernel خطی
رگرسیون منطقی[1]
اساساً مدل رگرسیون منطقی یکی از اعضای خانواده الگوریتم طبقهبندی نظارتشده است. رگرسیون منطقی رابطه بین متغیرهای وابسته و متغیرهای مستقل را از طریق برآورد احتمالات با استفاده از یک تابع لجستیک اندازهگیری میکند. در اینجا اگر در مورد متغیرهای وابسته و مستقل صحبت کنیم، متغیر وابسته متغیر کلاس هدف است که میخواهیم پیشبینی کنیم و از طرف دیگر متغیرهای مستقل ویژگیهایی هستند که میخواهیم از آنها برای پیشبینی کلاس هدف استفاده کنیم.
در رگرسیون منطقی، تخمین احتمالات به معنای پیشبینی احتمال وقوع رویداد است. بهعنوانمثال صاحب مغازه دوست دارد پیشبینی کند که مشتریای که وارد مغازه شده است، پلیاستیشن (برای مثال) خریداری میکند یا خیر. ویژگیهای بسیاری از مشتری وجود دارد – جنس، سن و غیره که توسط پیشخوان فروشگاه مشاهده میشود تا احتمال وقوع آن را پیشبینی کند، یعنی یک پلیاستیشن خریداری میکنند یا خیر. تابع منطقی منحنی سیگموید است که برای ساخت تابع با پارامترهای مختلف استفاده میشود.
پیشنیازها
قبل از استفاده از طبقهبندی کننده با استفاده از رگرسیون منطقی، باید بسته Tkinter را روی سیستم خود نصب کنیم. این بسته از آدرس https://docs.python.org/2/library/tkinter.html قابل نصب است. اکنون با استفاده از کد ارائهشده در زیر، میتوانیم با استفاده از رگرسیون منطقی، یک طبقهبندی کننده ایجاد کنیم.
در ابتدا برخی از پکیجها را وارد میکنیم.
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
حال باید دادههای نمونهای را که میتواند به شرح زیر انجام شود، تعریف کنیم:
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9], [2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
در مرحله بعد باید طبقهبندی کننده رگرسیون لجستیک را ایجاد کنیم، که میتواند به شرح زیر انجام شود –
Classifier_LR = linear_model.LogisticRegression(solver = ‘liblinear’, C = 75)
در آخرین نکته ولی با همان اهمیت، ما باید این طبقهبندی کننده را train کنیم. (آموزش دهیم)
Classifier_LR.fit(X, y)
حال چگونه میتوان خروجی را تجسم کرد؟ این کار میتواند با ایجاد تابعی به نام Logistic_visualize() انجام شود.
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() – 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() – 1.0, X[:, 1].max() + 1.0
در خط بالا حداقل و حداکثر مقادیر X و Y برای استفاده در شبکه mesh تعریف کردیم. علاوه بر این اندازه گام برای ترسیم شبکه mesh را تعریف خواهیم کرد.
mesh_step_size = 0.02
اجازه دهید شبکه mesh از مقادیر X و Y را به شرح زیر تعریف کنیم –
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))
با کمک کد زیر میتوان طبقهبندی کننده را روی شبکه mesh اجرا کرد –
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = ‘black’,
linewidth=1, cmap = plt.cm.Paired)
کد زیر مرزهای طرح را مشخص میکند –
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() – 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() – 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()
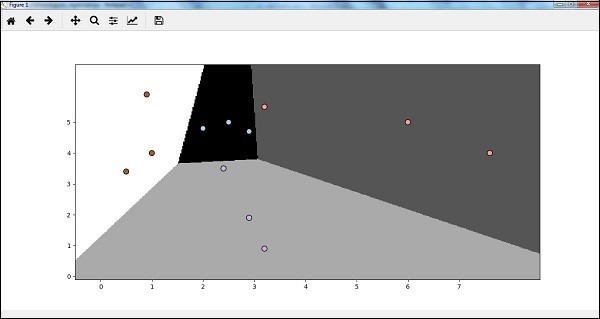
اکنون پس از اجرای کد، ما خروجی زیر را خواهیم داشت – یعنی طبقهبندی کننده رگرسیون لجستیک –
بخشهای دیگر مقاله را از لینکهای زیر بخوانید:
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت اول)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت دوم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت سوم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت پنجم)
هوش مصنوعی با پایتون – بخش پنجم – یادگیری نظارتشده : طبقهبندی (قسمت آخر)
[1] Logistic Regression
[1] Mesh
[1] Support Vector Machine